院試
合格しました.
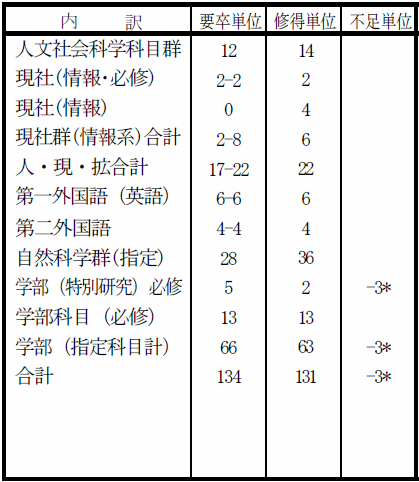
単位
フル単しました.のこり3単位は卒業研究です.
表題の通り22歳になっていました.意外とブログ記事を書いてなかったですね.
誕生日に対する認識がだんだん変わっているような気がしていて,節目とかめでたい日というよりはプレゼントがもらえる日という認知に傾きつつあります.
最近はゆっくり落ち着いていくという気持ちが薄れつつあるなあと思っています. 単位回収に院試対策,研究活動*1,もろもろが重なって,実際落ち着けないというのはあります.
もうちょっとがんばると学位が取れるかな,というのが分かってくると,それぐらいは取っておこうかという気持ちになり,そのためにはがんばる所でちゃんとがんばる必要があり,がんばりは行動ポイントを大きく消費するのだ……. ここには家計やら落ち着けない関係性やらも関っており,惰性を好む性格がここにきて災いしているという側面もありそう.
試験と院試が終わったらしばらくは落ち着けるはず,ということで今は落ち着きのない生活を送っております. 来期は研究活動が加わるので,夏休みぐらいは落ち着きたいですね.
プレゼントをいつでも受け付けています.
8/6に院試があるので,それ以降なら予定が合えばという感じになります.コミケ周辺は東京にいます.お金があまりないので,おごられると嬉しくなります.
*1:まだ卒研自体には着手していないけれど.
手元でgitリポジトリを作ったときに,よく wget https://raw.githubusercontent.com/github/gitignore/master/Python.gitignore -O .gitignore などのコマンドを打つのですが,環境によってwgetがなくてcurlだったり,そもそもgitリポジトリのルートディレクトリじゃなかったりすることがあります.
GitHubで作ったリポジトリだと最初からよしなにしてくれるのですが,手元でふとgitリポジトリを作ったときはそうもいかないものです.
Git Bashだとwgetがなくてイラつくなどもよく発生します.
ということでシェルスクリプトです.
使い方としては, gitignore.sh Python のように言語名を引数に渡してやると自動でダウンロードしてくれます.
#!/bin/sh LANGUAGE=$1 if [ -z "$LANGUAGE" ]; then echo "Usage: gitignore.sh <language name>" >&2 exit 2 fi GIT_BASE_DIR=`git rev-parse --show-toplevel` DEST=$GIT_BASE_DIR/.gitignore GITIGNORE_BASE_URL="https://raw.githubusercontent.com/github/gitignore/master" DOWNLOAD_URL=$GITIGNORE_BASE_URL/$LANGUAGE.gitignore if which wget > /dev/null 2>&1; then if ! wget $DOWNLOAD_URL -O $DEST; then echo "ERROR: cannot download $LANGUAGE.gitignore" >&2 exit 1 fi elif which curl > /dev/null 2>&1; then if ! curl -f $DOWNLOAD_URL -o $DEST; then echo "ERROR: cannot download $LANGUAGE.gitignore" >&2 exit 1 fi else echo "ERROR: either wget or curl is required." >&2 exit 1 fi
単にコマンドを置き換えただけだと面白くないので.特徴を連ねていきます.
wgetがあればwgetを,なければcurlを,それもなければエラーを出力するようになっているので,この環境はどっちが入っているのかを気にする必要がありません.
思考停止でコマンドを叩けば.gitignoreをルートディレクトリに落としてくれます.
wgetとcurlのオプションを使ってファイルのダウンロード先を指定しているので,言語名を間違えて 404: Not Found という.gitignoreを作ってしまうことはありません.
ruby と Ruby が異ったものとして扱われるので,常に正しい表記をしなければ正しくダウンロードしてくれません.
をずっと着回している. もう2年ぐらい服屋に行った記憶がなくて,気がついたらTシャツだけどんどん増えている.
いっぱい買うと送料無料になることがあるのでいっぱい買うとお得.
https://suzuri.jp/moko_oxygen/528905/t-shirt/s/blacksuzuri.jp
pdftotext を使えばできるpdftotext は,PDFファイルからテキストの情報を抜き出すことができるコマンドである.
これは単にテキストを抽出するだけでなく, -bbox-layout オプションを渡すことでbounding boxの詳細な情報も含めてXMLとして吐いてくれるのである.
このXMLをうまく使えばPDFファイルから発表タイトルを抜き出せるのではなかろうか.
今回は自分のスライドについて考えることにした.
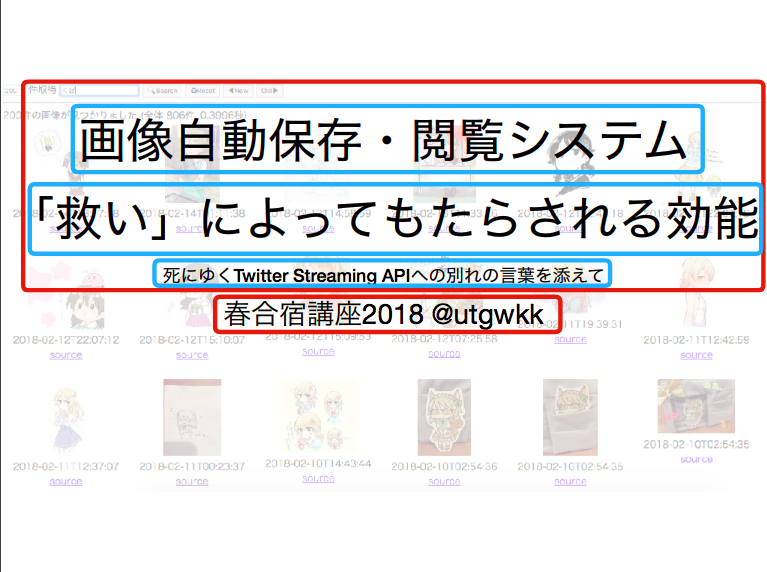
たとえば,このスライドを pdftotext にかけた結果は次のようになる.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>2018shinkan-pub</title> <meta name="Creator" content="Keynote"/> <meta name="Producer" content="Mac OS X 10.13.4 Quartz PDFContext"/> <meta name="CreationDate" content=""/> </head> <body> <doc> <page width="1024.000000" height="768.000000"> <flow> <block xMin="38.000000" yMin="76.200000" xMax="986.978000" yMax="496.200000"> <line xMin="38.000000" yMin="76.200000" xMax="338.000000" yMax="136.200000"> <word xMin="38.000000" yMin="76.200000" xMax="338.000000" yMax="136.200000">みなさん,</word> </line> <line xMin="38.000000" yMin="166.200000" xMax="815.000000" yMax="226.200000"> <word xMin="38.000000" yMin="166.200000" xMax="815.000000" yMax="226.200000">キーワード検索してますか?</word> </line> <line xMin="38.000000" yMin="256.200000" xMax="450.200000" yMax="316.200000"> <word xMin="38.000000" yMin="256.200000" xMax="450.200000" yMax="316.200000">してますよね?</word> </line> <line xMin="38.000000" yMin="346.200000" xMax="935.600000" yMax="406.200000"> <word xMin="38.000000" yMin="346.200000" xMax="935.600000" yMax="406.200000">それでは高速なキーワード検索を</word> </line> <line xMin="38.000000" yMin="436.200000" xMax="986.978000" yMax="496.200000"> <word xMin="38.000000" yMin="436.200000" xMax="986.978000" yMax="496.200000">支える技術についてお話しします.</word> </line> </block> <block xMin="135.000000" yMin="577.800000" xMax="889.080000" yMax="617.800000"> <line xMin="135.000000" yMin="577.800000" xMax="889.080000" yMax="617.800000"> <word xMin="135.000000" yMin="577.800000" xMax="404.440000" yMax="617.800000">2018/04/16</word> <word xMin="417.760000" yMin="577.800000" xMax="680.160000" yMax="617.800000">KMC例会講座</word> <word xMin="693.480000" yMin="577.800000" xMax="889.080000" yMax="617.800000">@utgwkk</word> </line> </block> </flow> </page> </doc> </body> </html>
これを図示するとこうなる.以下,枠線について,赤は <flow> ,青は <block>, 黄色は <line>, 緑色は <word> とする*1.
この場合については,
<block> をとる<line> 内の全ての <word> のtextContentを結合するといった手順を踏めばタイトルが復元できそうである.
最近の私のスライドは大体こちらの方式が適用できた. ざっと見た感触だと,めちゃくちゃに凝ったタイトルスライドを作るなどしなければこちらの方法でいけるのではなかろうかと思う.
pdftotext のPythonバインディングを見つける前にsubprocessでゴリッとやってしまった.
XMLを読み取るのがなかなか難しいし,可読性のためにもxml.etree.ElementTreeよりももうちょっといいものを使ったほうがいい気がする.
import sys import subprocess import xml.etree.ElementTree as ET filename = sys.argv[1] cmd = '/usr/bin/pdftotext -bbox-layout -f 1 -l 1 {0} -'.format(filename).split() result = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode('utf-8') tree = ET.fromstring(result) page = tree[1][0][0] first_block = page[0][0] titles = [] for line in first_block: words = [] for word in line: words.append(word.text) titles.append(' '.join(words)) title = ''.join(titles) print(title)
https://sugarheart.utgw.net/static/pdf/ にあるPDFだと1つを除いてうまくタイトルを取得することができた. Googleスライドのテーマを使ったものについてもうまくいった.
うまくいかなかったのは次のスライド.
これを pdftotext にかけると,複数の <flow> が出てくる.
この場合は最初の<flow> がタイトルだろうという判断がすぐできるのでスクリプトを改変して対応した.
自分のスライドのテーマやレイアウトの傾向をだいたい決めておけば,それに対応するスクリプトをすぐに用意できそう.
*1: <line>や<word>については,今回必要となるところしか図示していない.
バーチャルYoutuber鑑賞活動をしていると応援ソングのことを知ることがあり,魔王魂のフリーBGM素材であることを知った. 2018年になって魔王魂の名前を目にするとは思っていなかったし,まだ現役なんだなあと思った.
魔王魂の歌もの素材はYoutubeで試聴できるので,オススメをいくつか紹介します.
こちらは応援ソングです.